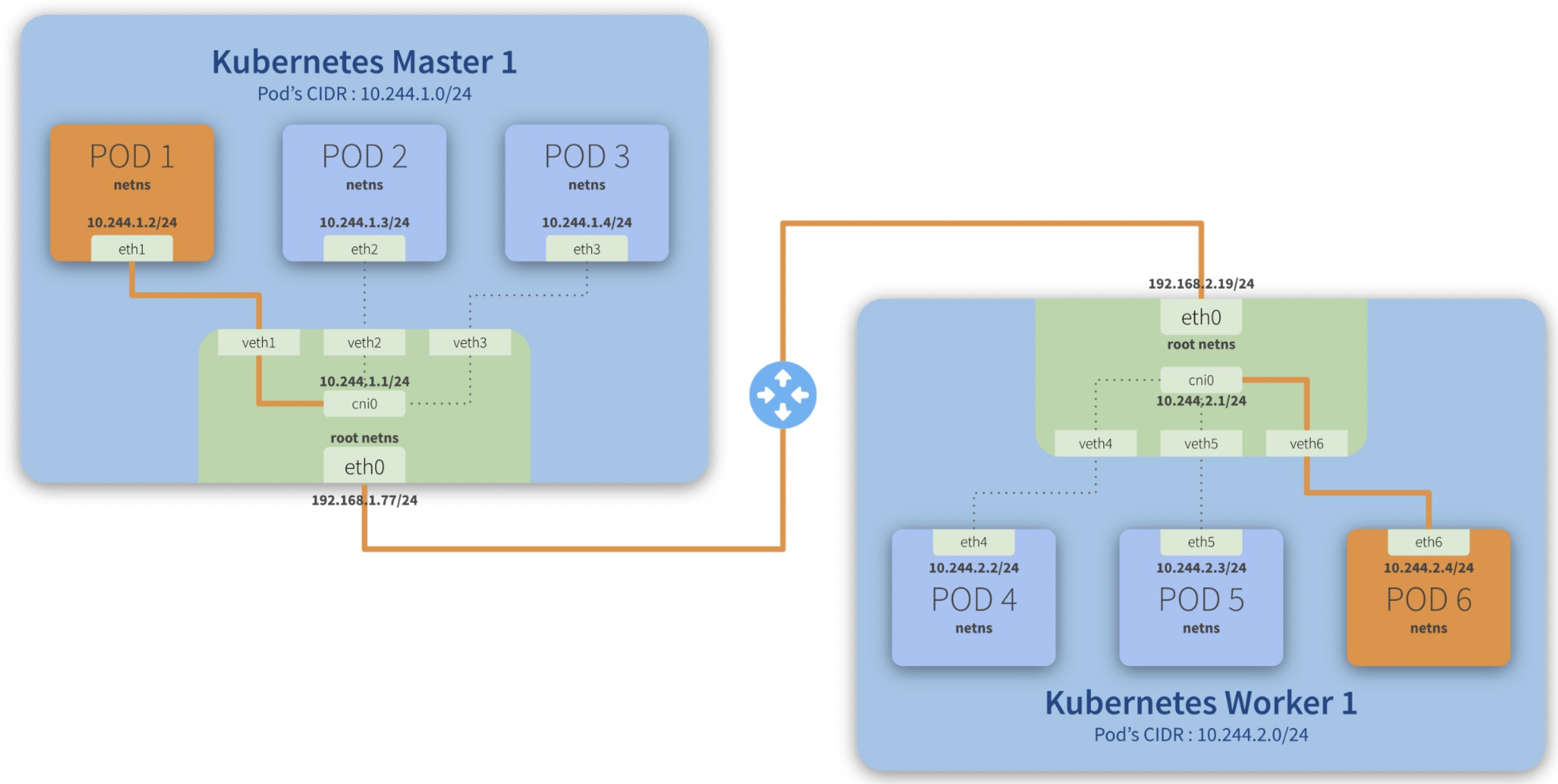
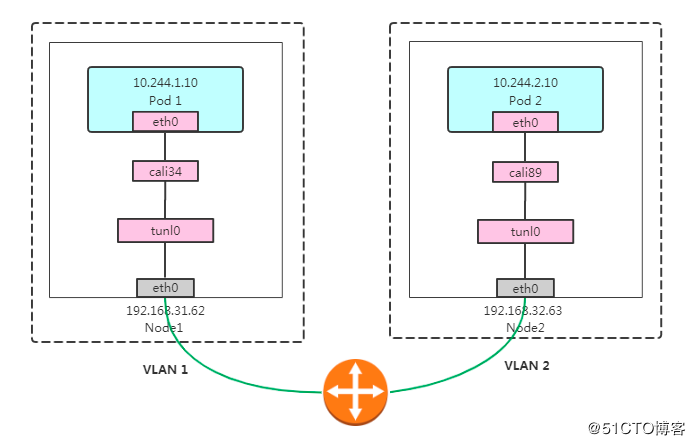
cni0 is a Linux network bridge device, all veth devices will connect to this bridge, so all Pods on the same node can communicate with each other, as explained in Kubernetes Network Model and the hotel analogy above.
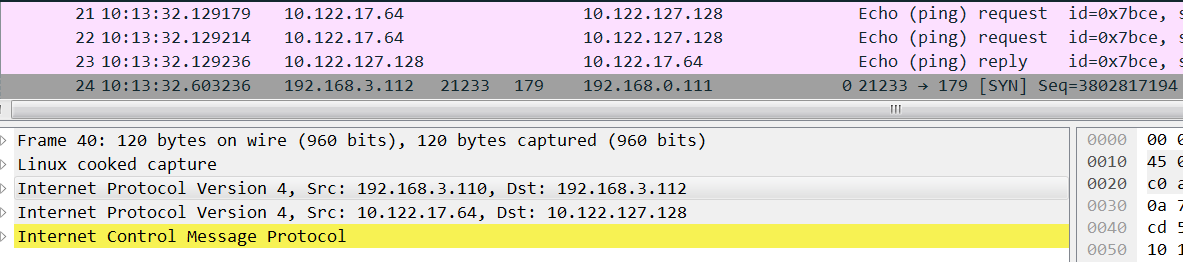
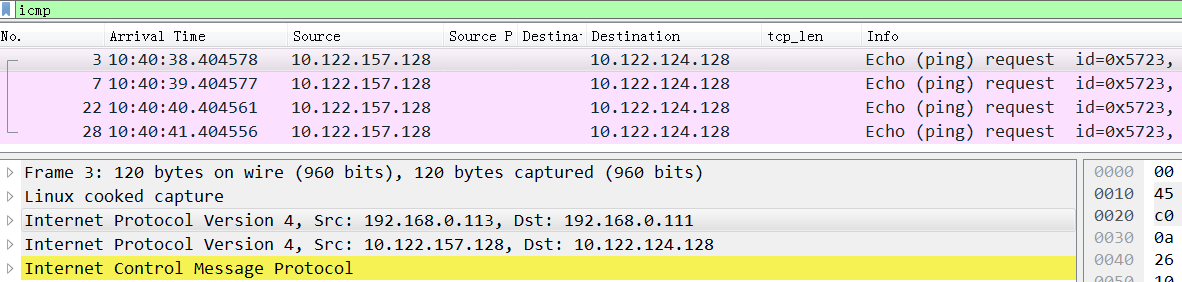
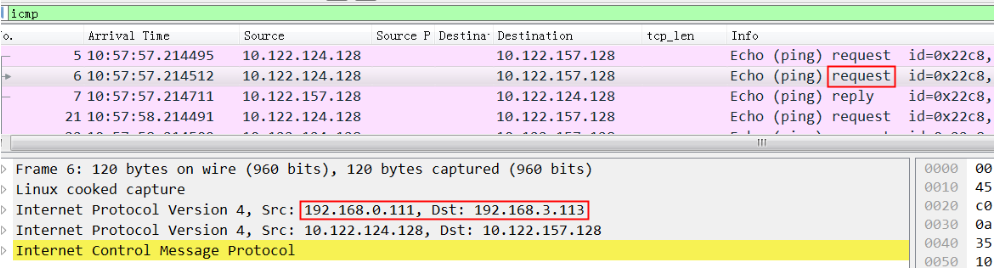
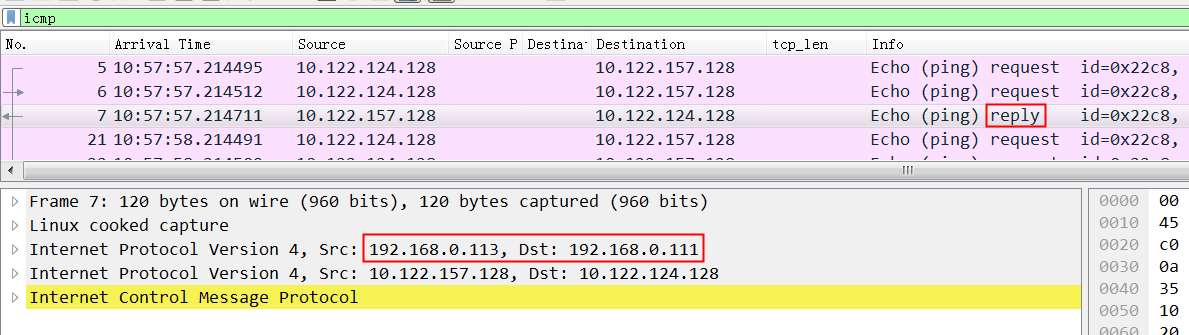
[root@az3-k8s-13 ~]# ip route |grep tunl0 10.122.17.64/26 via 10.122.127.128 dev tunl0 //这条路由不通 [root@az3-k8s-13 ~]# ip route del 10.122.17.64/26 via 10.122.127.128 dev tunl0 ; ip route add 10.122.17.64/26 via 192.168.3.110 dev tunl0 proto bird onlink
[root@az3-k8s-13 ~]# ip route |grep tunl0 10.122.17.64/26 via 192.168.3.110 dev tunl0 proto bird onlink //这样就通了
ip route del 192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.113 //同时将默认路由改到3.113 ip route del default via 192.168.0.253 dev eth0; ip route add default via 192.168.3.253 dev eth1
最终OK后,node4上的ip route是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
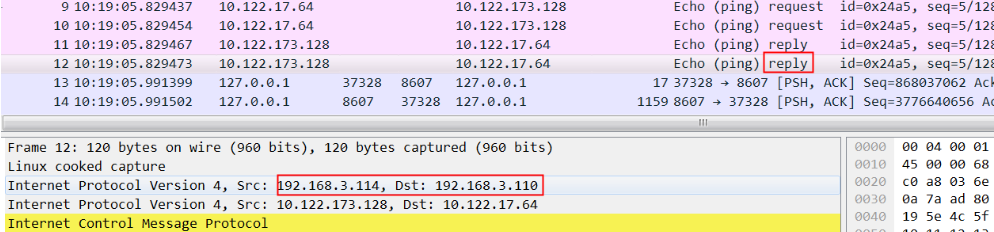
[root@az3-k8s-14 ~]# ip route default via 192.168.3.253 dev eth1 10.122.17.64/26 via 192.168.3.110 dev tunl0 proto bird onlink 10.122.124.128/26 via 192.168.0.111 dev tunl0 proto bird onlink 10.122.127.128/26 via 192.168.3.112 dev tunl0 proto bird onlink blackhole 10.122.157.128/26 proto bird 10.122.157.129 dev cali19f6ea143e3 scope link 10.122.157.130 dev cali09e016ead53 scope link 10.122.157.131 dev cali0ad3225816d scope link 10.122.157.132 dev cali55a5ff1a4aa scope link 10.122.157.133 dev cali01cf8687c65 scope link 10.122.157.134 dev cali65232d7ada6 scope link 10.122.173.128/26 via 192.168.3.114 dev tunl0 proto bird onlink 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 192.168.3.0/24 dev eth1 proto kernel scope link src 192.168.3.113
1004 [2021-10-27 10:49:08] ip netns add ren 1005 [2021-10-27 10:49:12] ip netns show 1006 [2021-10-27 10:49:22] ip netns exec ren route //为空 1007 [2021-10-27 10:49:29] ip netns exec ren iptables -L 1008 [2021-10-27 10:49:55] ip link add veth1 type veth peer name veth1_p //此时宿主机上能看到这两块网卡 1009 [2021-10-27 10:50:07] ip link set veth1 netns ren //将veth1从宿主机默认网络空间挪到ren中,宿主机中看不到veth1了 1010 [2021-10-27 10:50:18] ip netns exec ren route 1011 [2021-10-27 10:50:25] ip netns exec ren iptables -L 1012 [2021-10-27 10:50:39] ifconfig 1013 [2021-10-27 10:50:51] ip link list 1014 [2021-10-27 10:51:29] ip netns exec ren ip link list 1017 [2021-10-27 10:53:27] ip netns exec ren ip addr add 172.19.0.100/24 dev veth1 1018 [2021-10-27 10:53:31] ip netns exec ren ip link list 1019 [2021-10-27 10:53:39] ip netns exec ren ifconfig 1020 [2021-10-27 10:53:42] ip netns exec ren ifconfig -a 1021 [2021-10-27 10:54:13] ip netns exec ren ip link set dev veth1 up 1022 [2021-10-27 10:54:16] ip netns exec ren ifconfig 1023 [2021-10-27 10:54:22] ping 172.19.0.100 1024 [2021-10-27 10:54:35] ifconfig -a 1025 [2021-10-27 10:55:03] ip netns exec ren ip addr add 172.19.0.101/24 dev veth1_p 1026 [2021-10-27 10:55:10] ip addr add 172.19.0.101/24 dev veth1_p 1027 [2021-10-27 10:55:16] ifconfig veth1_p 1028 [2021-10-27 10:55:30] ip link set dev veth1_p up 1029 [2021-10-27 10:55:32] ifconfig veth1_p 1030 [2021-10-27 10:55:38] ping 172.19.0.101 1031 [2021-10-27 10:55:43] ping 172.19.0.100 1032 [2021-10-27 10:55:53] ip link set dev veth1_p down 1033 [2021-10-27 10:55:54] ping 172.19.0.100 1034 [2021-10-27 10:55:58] ping 172.19.0.101 1035 [2021-10-27 10:56:08] ifconfig veth1_p 1036 [2021-10-27 10:56:32] ping 172.19.0.101 1037 [2021-10-27 10:57:04] ip netns exec ren route 1038 [2021-10-27 10:57:52] ip netns exec ren ping 172.19.0.101 1039 [2021-10-27 10:57:58] ip link set dev veth1_p up 1040 [2021-10-27 10:57:59] ip netns exec ren ping 172.19.0.101 1041 [2021-10-27 10:58:06] ip netns exec ren ping 172.19.0.100 1042 [2021-10-27 10:58:14] ip netns exec ren ifconfig 1043 [2021-10-27 10:58:19] ip netns exec ren route 1044 [2021-10-27 10:58:26] ip netns exec ren ping 172.19.0.100 -I veth1 1045 [2021-10-27 10:58:58] ifconfig veth1_p 1046 [2021-10-27 10:59:10] ping 172.19.0.100 1047 [2021-10-27 10:59:26] ip netns exec ren ping 172.19.0.101 -I veth1 把网卡加入到docker0的bridge下 1160 [2021-10-27 12:17:37] brctl show 1161 [2021-10-27 12:18:05] ip link set dev veth3_p master docker0 1162 [2021-10-27 12:18:09] ip link set dev veth1_p master docker0 1163 [2021-10-27 12:18:13] ip link set dev veth2 master docker0 1164 [2021-10-27 12:18:15] brctl show brctl showmacs br0 brctl show cni0 brctl addif cni0 veth1 veth2 veth3 //往cni bridge添加多个容器peer 网卡
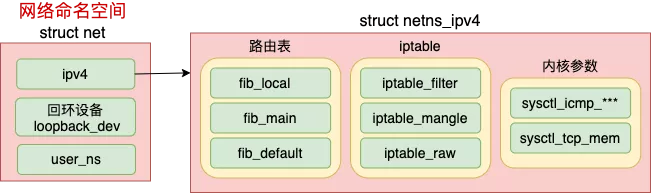
Linux 上存在一个默认的网络命名空间,Linux 中的 1 号进程初始使用该默认空间。Linux 上其它所有进程都是由 1 号进程派生出来的,在派生 clone 的时候如果没有额外特别指定,所有的进程都将共享这个默认网络空间。
所有的网络设备刚创建出来都是在宿主机默认网络空间下的。可以通过 ip link set 设备名 netns 网络空间名 将设备移动到另外一个空间里去,socket也是归属在某一个网络命名空间下的,由创建socket进程所在的netns来决定socket所在的netns
1 2 3 4 5 6 7 8 9 10 11 12
//file: net/socket.c intsock_create(int family, int type, int protocol, struct socket **res) { return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0); }